リアルタイム
ニューラル音声合成
・リアルタイムなニューラル音声合成

入力された文章から音声を生成する音声合成の技術は,Smart Speaker等で馴染みのある技術だと思います.近年では深層学習を取り入れることでその品質が劇的に向上しており,とても盛んに研究がなされている分野です.特に最近ではスマートフォン等のモバイル端末でも扱えるように,限られた計算資源で高速に合成が可能な手法が多く研究されています.
※ 図1の引用元
https://www.apple.com/jp/siri/
https://developer.amazon.com/ja-JP/alexa
https://www.yamaha.com/ja/about/ai/vocaloid_ai/
https://ec.crypton.co.jp/pages/prod/virtualsinger/cv01
http://nicotalk.com/charasozai.html
・音響モデルとボコーダ
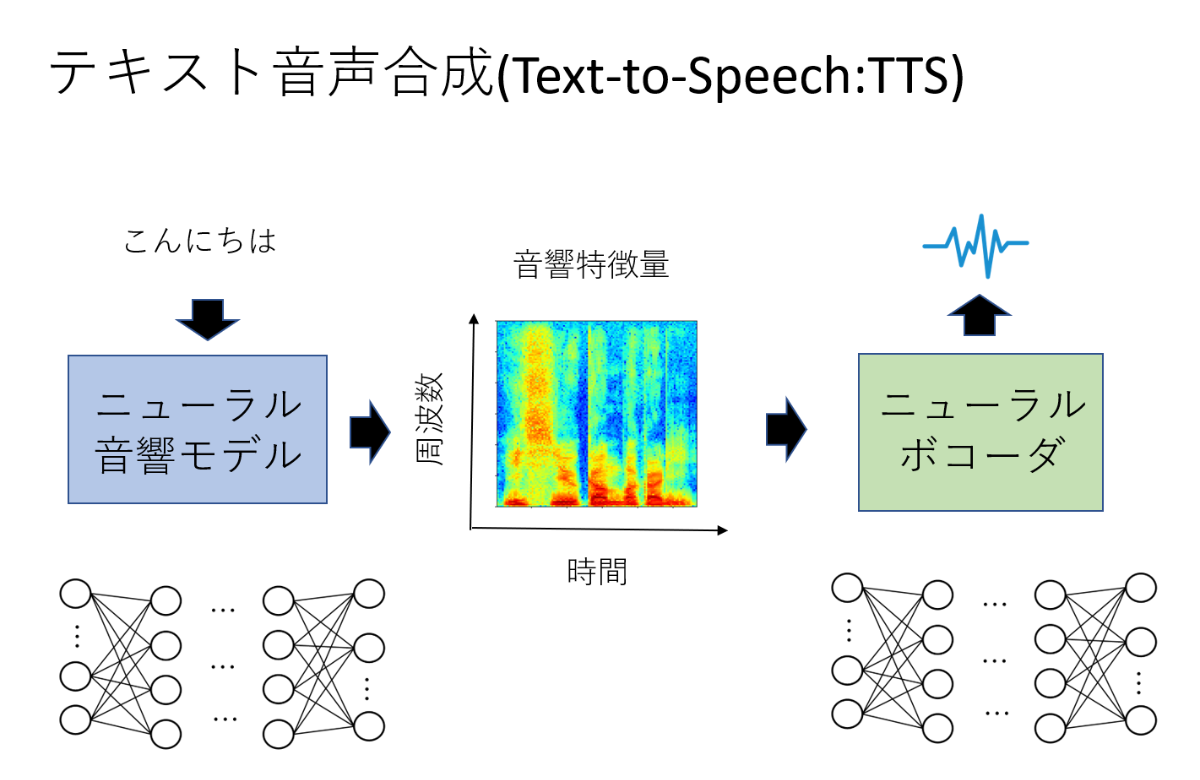
音声合成モデルは大きく音響モデルとボコーダの2つから構成されます.音響モデルでは入力されたテキストから対応する音響特徴量を推定します.音響特徴量とは,音声をその性質をよりよく表した表現に変換したもので,スペクトログラムなどがあります.ボコーダは得られた音響特徴量から音声を復元します.
・ニューラルボコーダ
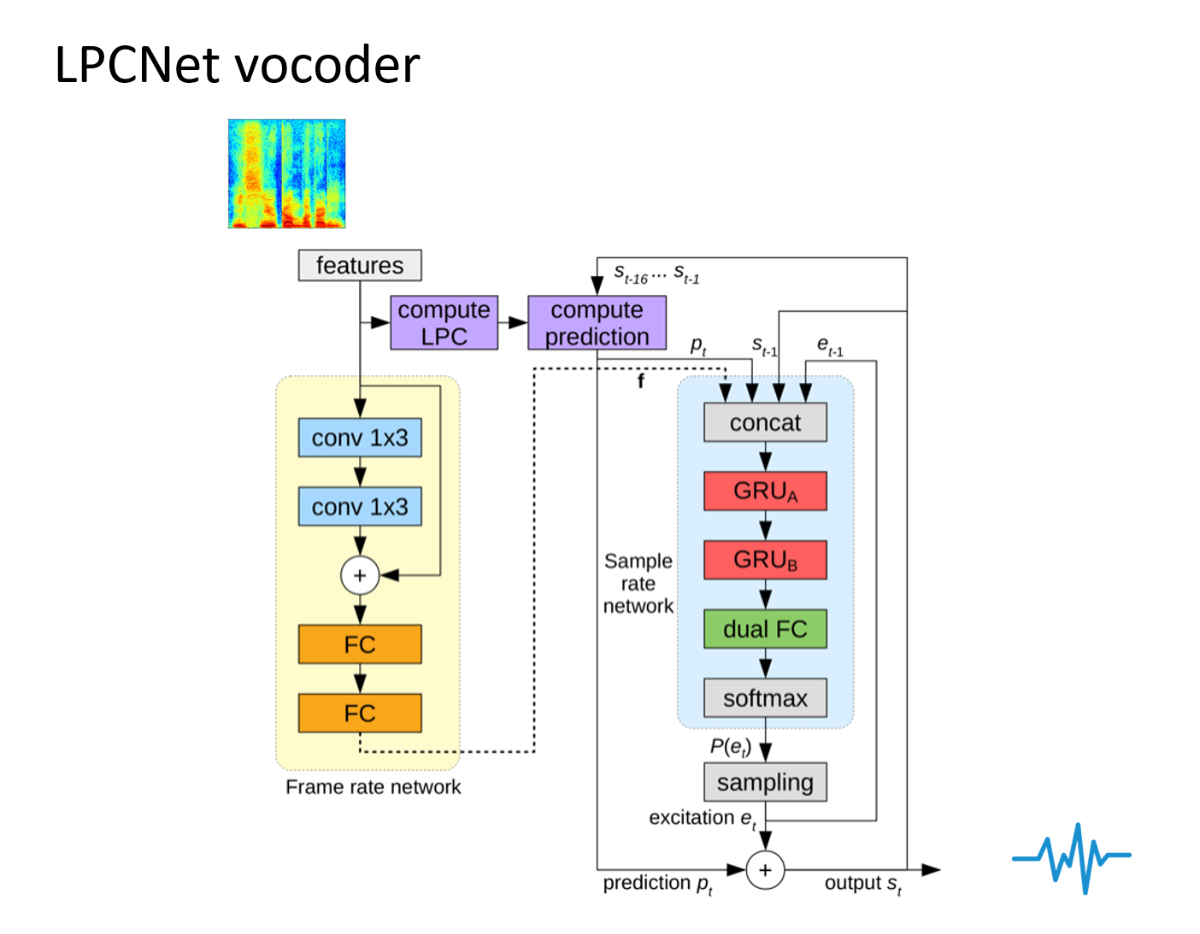
ボコーダは,以前は機械的なアルゴリズムを用いて音声を復元していましたが,音響特徴量は音声の位相情報などが欠落していることから完全な復元が出来ず,品質に限界がありました.そこでニューラルネットワークを用いてボコーダを構成することでその問題を克服し,自然音声と見分けがつかないほどの高品質な音声を合成することが可能になりました.私たちの研究室では,学習データ量や計算資源が限られている環境でも高品質な合成が可能なニューラルボコーダとして,Full-band LPCNetを提案しました.